4. Normal likelihood with mean and variance unknown#
4.1. Normal likelihood with noninformative prior#
Let be \(Y_1,\ldots,Y_n|\mu,\sigma^2\overset{iid}{\sim}\textsf{Normal}(\mu,\sigma^2)\), so the likelihood evaluated in our sample is given by
In Chapter 6 we’ll see that, because \(\mu\) and \(\sigma\) are parameters of location and scale, respectively, then a noninformative prior is given by
Thus,
where
4.1.1. Distribution of \(\mu|\sigma^2,\mathbf{Y}\)#
From the previous expression we can deduce the distribution of \(\mu|\sigma^2,\mathbf{Y}\) taking \(\sigma^2\) as a constant,
That is,
4.1.2. Distribution of \(\sigma^2|\mathbf{Y}\)#
To get the distribution of \(\sigma^2|\mathbf{Y}\) we can marginalize \(p(\mu,\sigma^2|\mathbf{Y})\) with respect to \(\mu\). That is, we can calculate the next integral
which corresponds with a scaled inverse \(\chi^2\) with \(n-1\) degrees of freedom and scale parameter \(s^2\), that is
4.1.3. Distribution of \(\mu|\mathbf{Y}\)#
Analogously, we can obtain the distribution of \(\mu|\mathbf{Y}\) marginalizing the joint posterior, that is
This integral can be calculated making the change of variable
Then,
which corresponds to the kernel of a \(t\) distribution with \(n-1\) degrees of freedom, with location parameter \(\bar{y}\) and scale parameter \(s/\sqrt{n}\). That is,
4.1.4. Connection with the frequentist statistics#
In other words, considering noninformative priors for \(\mu\) and \(\sigma^2\), we have that
Meanwhile, the central limit theorem stablishes that
We also prove that
which coincides with the result of the frequentist statistics: $\(\sqrt{n}\frac{\bar{y}-\mu}{s}\Big|\mu\sim t_{n-1}.\)$
4.1.5. Simulate from the posterior predictive distribution#
Once we obtained the posterior distributions, it is easy to simulate from the posterior predictive distribution, we just need to execute the following steps:
Simulate \(\tilde{\sigma}^2\sim\textsf{Inverse-}\chi^2(n-1,s^2).\)
Simulate \(\tilde{\mu}\sim\textsf{Normal}(\bar{y},\tilde{\sigma}^2/n)\).
Simulate \(\tilde{Y}\sim\textsf{Normal}(\tilde{\mu},\tilde{\sigma}^2)\).
4.2. Normal - Inverse-\(\chi^2\) prior for the normal likelihood#
It is well-known that the prior Normal - Inverse-\(\chi^2\) forms a conjugate model for the normal likelihood. If
and \(Y_1,\ldots,Y_n|\mu,\sigma^2\overset{iid}{\sim}\textsf{Normal}(\mu,\sigma^2)\). Then,
where
and \(s^2=\frac{1}{n-1}\sum_{i=1}^n(y_i-\bar{y})^2\).
More over,
and
4.3. Bayesian statistical process control#
Because
then
4.3.1. Control intervals for \(\bar{Y}\)#
Let be
Thus, an approximate prediction interval of posterior probability \((1-\alpha)\times 100\%\) for the sample average \(\bar{Y}_m\) is given by
where \(q_{t_{\nu_n}}(1-\alpha/2)\) denotes the quantile of probability \(1-\alpha/2\) of a \(t\) distribution with \(\nu_n\) degrees of freedom.
In the field of statistical process control, the extremes of the prediction interval are called lower and upper control limitis (LCL and UCL, respectively). It is usual to consider \(\alpha=0.002\), so the interval coincides with the normal case of \(\pm 3\sigma\).
4.3.2. Control intervals for \(S\)#
When monitoring a process, it’s important to check not only its mean but also the behavior of its variability. Unfortunately, it is not easy to find theoretical control limits for the sample deviaton \(S\). But not everything is lost, we can use simulation to solve the problem! We just need to perform the following steps:
Simulate \(J\) samples \(Y_1,\ldots,Y_n\) from the posterior predictive distribution, with \(J\) large.
The sample deviation of each one of the simulated samples, \(S_1,\ldots,S_J\) will follow the same distribution that the sample deviattion \(S\) of our original observations.
Using the sample \(S_1,\ldots,S_J\), we calculate its mean \(\bar{S}\) and standard deviation \(S_S\).
We can define the \(\pm 3\sigma\) control limits as
4.3.3. Simulated control intervals for \(\bar{Y}\)#
Similarly, we can obtain a sample of the sample average \(\bar{Y}_1,\ldots,\bar{Y}_J\) and estimate its control limits as:
4.3.4. Setting the hyperparameters#
Because a priori we know nothing about the process, we can use the reference prior given by
which is obtained setting the hyperparameters in the following values:
4.3.5. Example#
Note
The data for this example were taken from Table 6.3 of [Mon19], seventh edition.
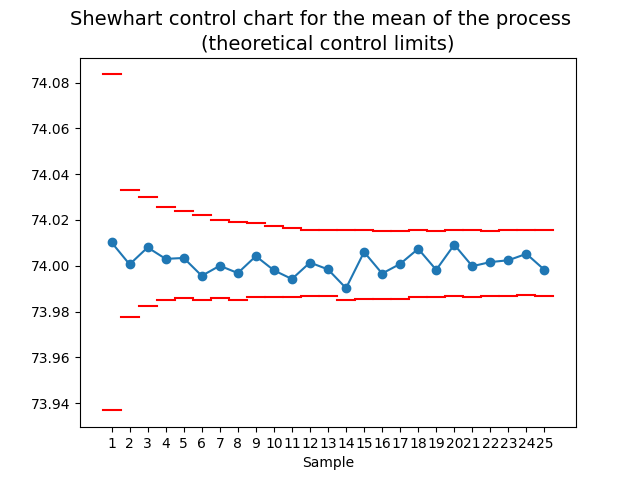
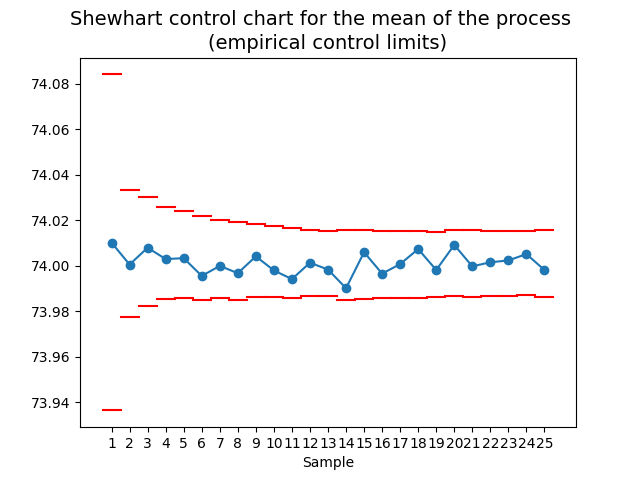
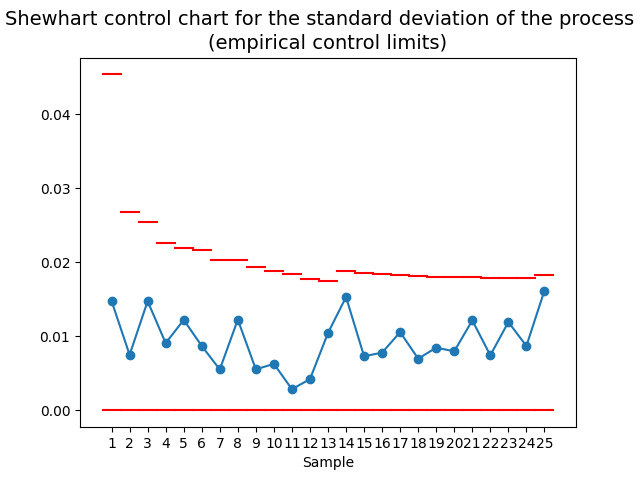
Shewhart control charts
Different control charts have been proposed for different purposes. The type of control charts presented here are known as Shewhart control charts.
See also
For interested readers in the field of Statistical Quality Control, of which control charts form part, I recomend the book [Mon19].
4.4. Predictive distribution of the normal likelihood with unknown variance#
Back in Chapter 3 we study the case where our data comes from a normal distribution with unknown variance. We found that the conjugate distribution in such case is an scaled inverse \(\chi^2\) distribution, we are now ready to deduce its posterior predictive distribution.
Consider the posterior distributions of the Normal - Inverse-\(\chi^2\) prior for the normal likelihood,
and
Note that
That is,
On the other hand, consider the model with \(\mu\) known but \(\sigma^2\) unknown,
then
where
and
Note that
by analogy, we deduce that
Furthermore, in this case the noninformative prior is acgieved setting \(\nu_0=0\) and \(\sigma_0^2>0\), so \(\nu_n=n\) and \(\sigma_n^2=v\). Then,
or, equivalently